Real numbers. Real sites.
Demo: TechCrunch in One Command
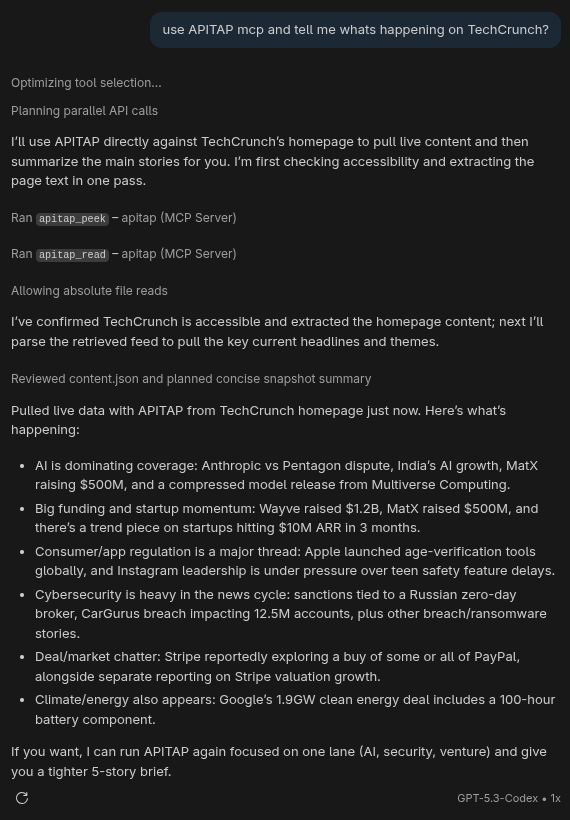
Browser: ~8,000 tokens → ApiTap: ~200 tokens = 97% reduction
Works in any AI assistant. One command. Live data.
Reddit: 125,805 tokens of HTML → 641 tokens via ApiTap. Same data.
These aren't mock numbers. Run
apitap read https://news.ycombinator.com/ yourself and count the tokens.